Beyond Vector Search
Jan 4, 2026
ThirdAI Automation
Introduction
Retrieval-Augmented Generation, commonly known as RAG, has become a foundational component of enterprise AI copilots, knowledge assistants, and automation platforms. Most organizations begin their RAG journey with a familiar pipeline: documents are embedded, user queries are embedded, and vector similarity search is used to retrieve relevant context. For simple, factual questions, this approach works reliably.
However, real enterprise questions are rarely simple.
In practice, users ask about comparisons, root causes, timelines, dependencies, interactions across multiple entities, and domain-specific scenarios. They often rely on shorthand, inconsistent terminology, or incomplete phrasing. Traditional RAG systems, which depend largely on semantic similarity, struggle to interpret this kind of complexity.
To address these limitations, we developed an Enhanced RAG system that introduces structure, reasoning, and intent awareness into the retrieval process. Rather than focusing on incremental optimizations to the vector store, we concentrated on a more fundamental challenge:
Helping the system understand what the question means, not just what it says.
Where Traditional RAG Falls Short
Most RAG implementations follow a straightforward and widely adopted pipeline. Documents are embedded, queries are embedded, vector similarity search is performed, and the most relevant chunks are passed to a large language model.
While this approach appears elegant, it begins to break down in several common scenarios.
Multi-Part or Layered Questions
Vector search treats each query as a single-hop request, even when the underlying question implicitly requires multiple steps of reasoning. As a result, the system retrieves fragments of information without understanding how they should be combined.
Relationship-Dependent Questions
Many enterprise questions depend on how two or more entities relate to one another. Embedding similarity alone cannot reliably capture these relationships, especially when the relevant information is distributed across different documents.
Terminology Mismatch
Users frequently phrase questions differently from how concepts are documented. Without flexible interpretation, retrieval becomes fragile and overly sensitive to wording.
No Sense of Intent or Planning
Vector search retrieves content that looks similar at the surface level, not content that best supports the user’s intent or the structure of the question.
Because of these limitations, traditional RAG systems often feel inconsistent. They may perform well in some cases, yet fail unexpectedly when faced with complex analytical queries.
What Enhanced RAG Brings to the Table
Our approach introduces several complementary capabilities that work together to overcome these challenges, without requiring users to modify how they naturally ask questions.
1. Knowledge Graph–Aware Retrieval
We enhance retrieval by giving the system a lightweight understanding of how concepts relate to one another, including process steps, components, causes, effects, and dependencies. This transforms retrieval from simple word matching into concept-aware search.
Instead of asking, “Which sentences look similar to the query?” the system begins to ask, “Which concepts, connected ideas, and dependencies are relevant to this question?”
Example
Consider the query:
“How can a manufacturing defect early in fabrication end up causing failures months later in the field?”
A knowledge graph–aware system traces the conceptual chain from the early defect, to material behavior, to stress propagation, and finally to reliability failure. It retrieves evidence across all of these connected concepts, something a pure vector search approach is unable to do.
2. Query Rewriting to Capture User Intent
Users rarely express questions using the precise terminology found in technical documentation. Instead, they rely on informal language, shorthand, local jargon, or partial descriptions.
Query rewriting addresses this gap by generating multiple alternate versions of the original question. These variations may be more technical, more general, more specific, or paraphrased, allowing retrieval to align with what the user intended rather than the exact words they typed.
Example
If a user asks, “Why are we getting these weird voids?” rewritten variants might include questions such as:
“What mechanisms lead to void formation during the process?” or “Which operating conditions create internal cavities?”
By expanding the query in this way, the system avoids missing relevant evidence simply because of casual or imprecise wording.
3. Multi-Hop Reasoning for Complex Questions
Some questions inherently require multiple reasoning steps. Rather than attempting to answer everything at once, the system identifies the internal structure of the question and decomposes it accordingly.
Evidence is retrieved step by step, and the results are then synthesized into a coherent and contextually accurate response.
Example
For the query, “Why do deep structures develop voids during fabrication, how does that impact final reliability, and what can be done to mitigate it?” the system interprets this as three linked questions: identifying the root cause, connecting that cause to downstream effects, and retrieving mitigation strategies.
The final response traces the full chain from root cause to physical effect, reliability impact, and mitigation. This mirrors the way an experienced engineer would reason through the problem and avoids shallow or incomplete answers.
4. Hybrid Retrieval with Smart Reranking
Enhanced RAG combines multiple retrieval signals, including vector search for semantic breadth, knowledge graph context for relationship awareness, and rewritten queries for intent flexibility.
Each signal produces different types of evidence. The system evaluates these independently, reranks them based on relevance, and selects the strongest combination. This ensures that important information is retained, irrelevant matches are filtered out, and the final context remains dense and aligned with the question.
Retrieval becomes a curated process rather than a simple closest-match operation.
What This Unlocks for Enterprises
By moving beyond pure embedding similarity, Enhanced RAG evolves into a reasoning layer rather than a simple search mechanism.
Enterprises benefit from higher-quality answers to complex questions, greater resilience to phrasing and terminology differences, more consistent understanding across teams, improved recall and precision, and AI copilots that users can trust.
When retrieval improves, reasoning improves, and trustworthy outputs follow.
Moving Toward the Next Frontier
Enhanced RAG brings enterprises most of the way toward reliable, intent-aware, reasoning-capable AI assistants. By combining knowledge graph awareness, query rewriting, multi-hop reasoning, and hybrid retrieval, many of the limitations of vector-only RAG are resolved.
However, achieving the level of reliability required for mission-critical workflows demands additional techniques. These next-level methods will be explored in upcoming work, where we will show how they complement Enhanced RAG to deliver expert-level consistency and depth.
The Future of Retrieval Is Hybrid, Structured, and Intent-Aware
Traditional RAG was an important first step in bringing large language models closer to enterprise knowledge. However, it was never designed to handle the complexity, ambiguity, and reasoning depth required by real-world questions.
Enhanced RAG represents the next evolution.
Where classic RAG answers questions primarily based on surface-level semantic similarity, Enhanced RAG answers based on deeper signals:
relationships, through knowledge graph awareness
intent, through query rewriting
reasoning, through multi-hop decomposition
robust evidence selection, through hybrid retrieval
This shift moves organizations from systems that work intermittently to systems that consistently understand what a question truly requires.
If you are ready to adopt retrieval that behaves more like a thoughtful analyst and less like a keyword engine, ThirdAI Automation can help bring Enhanced RAG into your enterprise workflows and AI systems.
Why Vision-Aware RAG Matters
A Side-by-Side Look at How AI Understands Technical Figures
1. The Actual Figure Being Analyzed
See content credentials

Figure 11 from B. Toleno, T. White, R. Zhang, and J. Bowin, “Enhancing Reliability of PB-Free Solder Joints,” Henkel Corporation, Irvine, CA, USA, Materials Tech White Paper, n.d.
The figure is a microscopic solder joint image with clear visual indicators, including cracks, interfaces, and red arrows highlighting specific failure regions.
2. How Traditional AI Models Interpret It
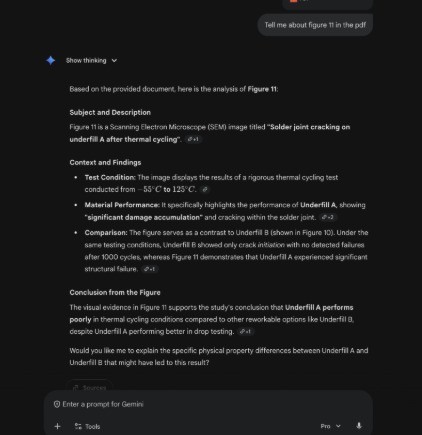
What Happens Here
Popular AI assistants such as Gemini generate long, confident explanations. However, the content of these explanations comes almost entirely from:
the figure caption
neighboring text in the PDF
assumptions based on the paper’s overall topic
The model does not describe the image itself.
There is no mention of where cracks appear, how fractures propagate, what the arrows indicate, the geometry of the joint, or any direct visual observation.
This is the limitation of caption-only interpretation.
Most AI systems today do not actually analyze the pixels in technical figures.
3. How Our Platform Interprets the Same Figure

What Happens Here
Our system describes what is visibly present in the image itself, including:
crack initiation points
the locations indicated by arrows
lower-interface fracture paths
surface texture and damage distribution
scale bar, magnification, and SEM context
This visual interpretation is then combined with the surrounding text to produce a grounded and coherent explanation.
This is possible because our system does not rely on captions alone. It relies on vision, retrieval, and reasoning working together.
4. How Our Approach Works
We designed our platform so that figures in technical documents are treated as first-class knowledge objects, not decorative attachments.
A. We Actually Look at the Image
Most AI systems only read the caption. Our system analyzes the pixels themselves, including cracks, arrows, contours, interfaces, and other features engineers care about.
This allows the assistant to describe what the figure actually shows, not just what the surrounding text suggests.
B. We Convert Visual Meaning Into Searchable Knowledge
The system generates a written description of each figure that captures its visual details.
As a result:
images become searchable
images become retrievable
images become part of the document’s semantic meaning
For example, a user can ask: “Show me figures showing interface cracking.”
The system can now find relevant figures based on visual content, not just captions.
C. We Combine Visual and Textual Evidence Through Enhanced RAG
When a user asks a question:
text retrieval brings in the experimental setup and conclusions
image retrieval contributes the visual findings
reasoning merges both into a single grounded answer
The user receives both what the study claims and what the image visually demonstrates.
D. We Avoid Caption-Only Hallucination
Traditional systems place excessive trust in captions. Our system instead trusts the image and its surrounding context.
This prevents:
generic explanations
oversimplified claims
errors caused by relying on nearby text
long answers that ignore what the figure actually shows
5. Why Our Results Look Different and Better
A. We Describe What the User Can Actually See
When an SEM image contains visible cracks and highlighted regions, our system explicitly describes them. Caption-only systems cannot do this.
B. We Merge Vision, Retrieval, and Reasoning
Rather than relying on text alone, our approach integrates multiple modalities into a single reasoning pipeline.
C. Engineers Receive Actionable Insight
The output includes concrete failure modes, crack behavior, and figure-specific observations, not generic summaries.
D. Images Become Searchable Knowledge
Users can ask questions about visual features across an entire library of PDFs, something that was previously not possible.
E. The Answers Are Grounded and Trustworthy
The explanations are derived from what is actually present in the figure, not from assumptions based on nearby text.
Conclusion
When analyzing scientific and engineering documents, images often carry critical information that captions alone cannot capture.
This comparison highlights a fundamental difference:
Popular AI assistants describe the topic. Our vision-aware RAG describes the actual figure.
If you want an AI assistant that truly understands technical documents, not only the words but also the images themselves, vision-aware retrieval represents the future.
Bring Your Data, Leave With Answers
CONTACT US TO LEARN MORE
Your Data, Your Control
Your Data, Our Highest Priority
We safeguard your information with advanced security protocols and strict compliance standards, including CCPA, ISO, and SOC 2. Learn more in our Privacy Policy.



Get In Touch
Don’t let complexity slow you down.
See how Industrial AI can supercharge your operations.
ThirdAI Automation empowers engineers with agentic AI to pinpoint root causes, accelerate troubleshooting, and surface critical insights—reducing downtime and maximizing efficiency.
Reach out to discover how we can help transform your workflows.
Product
Company
Who We Help
Resources
Join Our Newsletter
© 2026 ThirdAI Automation. All Rights Reserved.